湖北大学生命科学学院、省部共建生物催化与酶工程国家重点实验室高级实验师陈前军团队日前在计算机信息系统顶刊Information Sciences(中科院一区Top,CCF-B类杂志)上发表题为“A supervised data augmentation strategy based on random combinations of key features”(一种基于关键特征随机组合的监督数据增强策略)的研究论文,该论文提出了一种新型深度卷积神经网络样本数据增强策略,用以解决深度学习模型训练过程中样本量不足问题,命名为SDA-KFE。硕士生丁永昌、刘畅、朱海峰为共同第一作者,陈前军老师为通讯作者,湖北大学为第一单位(图1所示)。

图1文章首页
近年,以深度学习为代表的人工智能技术在计算机视觉、自然语言处理和蛋白质结构预测等诸多领域中发挥着越来越重要的作用,然而深度学习模型训练过程中存在着样本稀缺、获取困难、标注费时费力等突出问题,这极大制约了深度学习模型精度和鲁棒性的提升。陈前军老师团队在前期发表NNI-SRI深度神经网络模型解释算法的基础上,通过NNI-SRI分割出样本关键特征区域(特征激活程度不同,定量分析),再随机组合关键特征区域合成含有丰富特征信息的虚拟样本,达到极大化利用样本中既有特征信息目的(过采样),以此提高模型分类准确度,算法思想如图2所示。
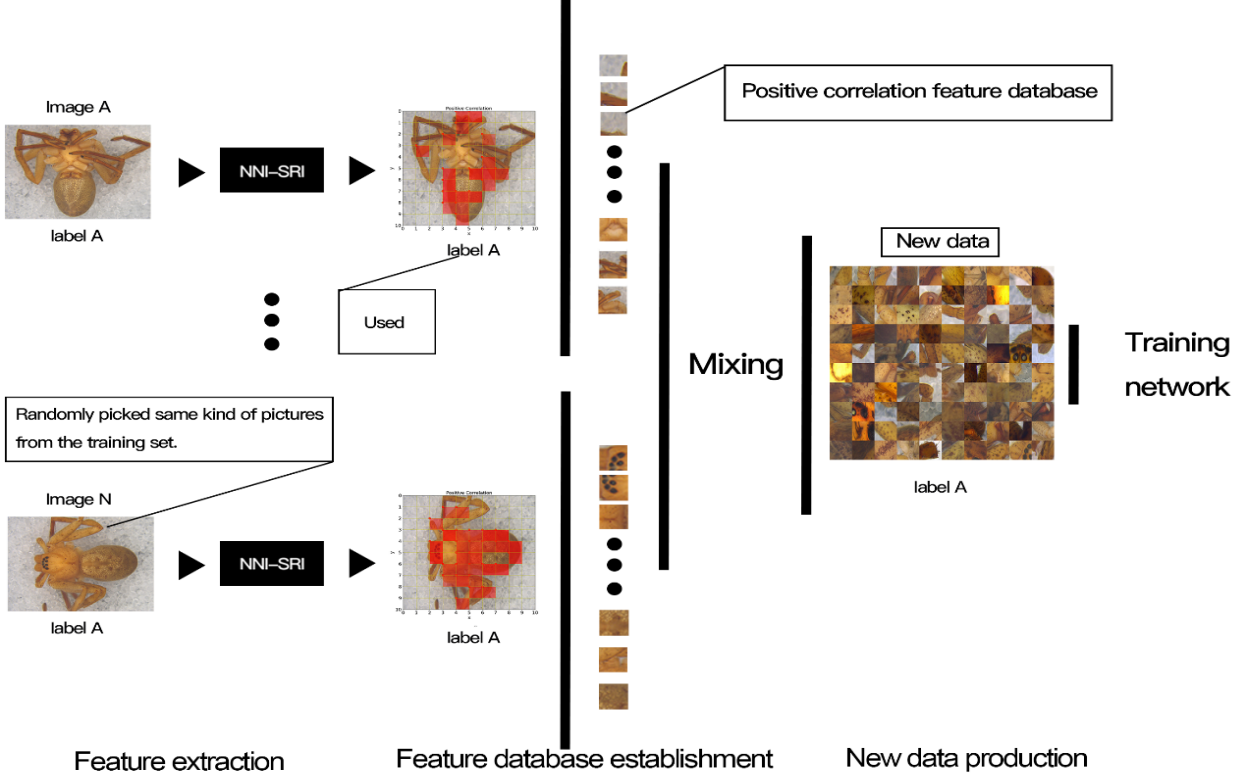
图2 SDA-KFE算法思想
研究人员为验证算法思想的有效性,设计了多组对比实验,从扩增策略对网络模型的精确度、稳定性和鲁棒性影响多维度进行评测。实验结果表明,在自研浅层神经网络、通用深度神经网络,自有蜘蛛样本、通用花卉和猫狗样本环境中,均取得了不错的实验结果,证明该样本扩增策略有效,模型的精度、稳定性表现良好,论文被部分审稿人评议为“Good Work”,模型精度、鲁棒性表现如图3所示。
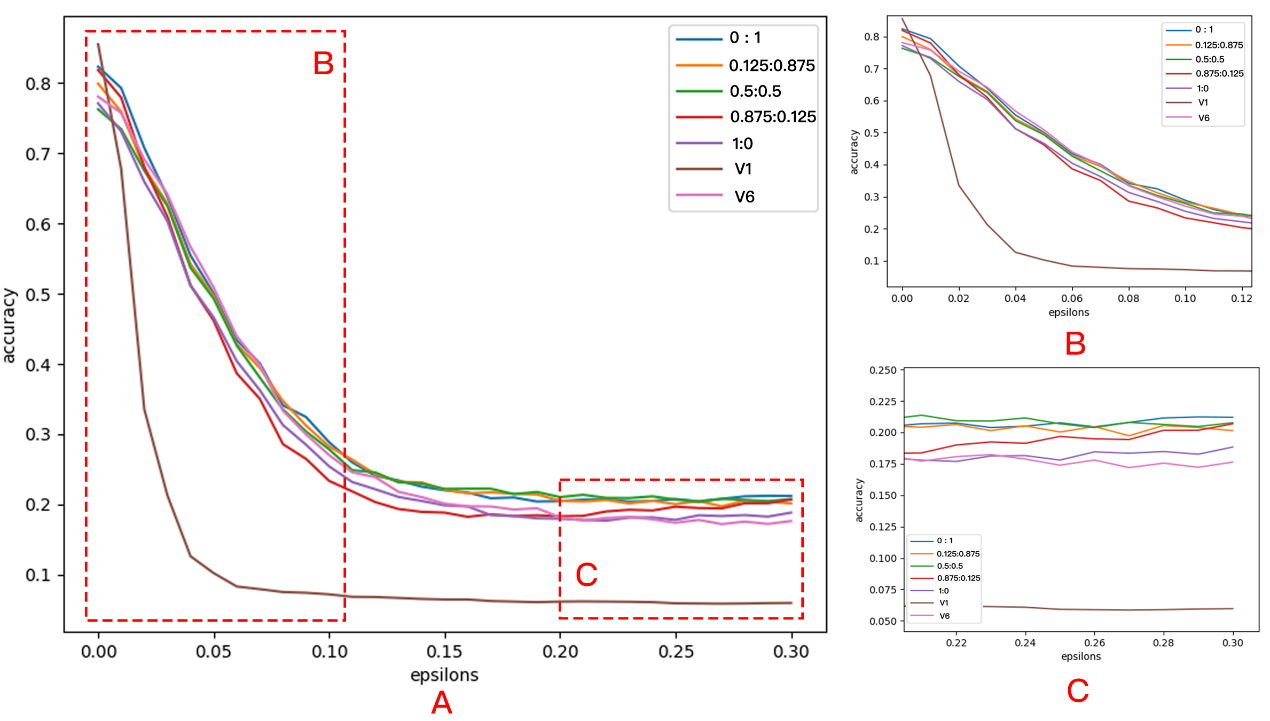
图3 SDA-KFE在FSGM评测标准中不同虚拟样本扩增比例模型鲁棒性表现(V1为对照组),图A显示干扰因素增加时各种扩增比例精度变化情况,图C能够明显体现出SDA-KFE对模型鲁棒性的正向作用。
据悉,陈前军老师团队一直致力于计算机软件、人工智能基础理论的研究和开发工作。近年来,先后以第一或通讯作者发表SCI论文6篇、承接横向课题超过15项,研发的葛洲坝人才招聘系统、运百跨境电商物流管理系统、湖北省公安厅执法资格大规模在线考试系统、湖北文化产业网和广州地铁设计研究院智慧规划平台等信息系统运行稳定、效果良好,得到用户一致好评。
文章链接:https://www.sciencedirect.com/science/article/pii/S0020025523003341



